Conversational UX & AI agent: Fast, scalable resolutions for customer service teams
Zaapi | Conversational UX & AI
Conversational UX & AI agent: Fast, scalable resolutions for customer service teams
Designed a no-code AI chat agent and conversational UX that uses customer context before answering, cites sources, follows policy, stays human-controlled, and speaks in our brand voice—delivering faster resolutions, higher first-contact resolution, and scaled support without new hires.
+750%
More AI feature usage (click) after introducing the new AI branding and relocating the button
+100%
Increase in messages sent by Zaapi AI from start of Q1 to end of Q2 2025 after launching AI thinking and performance dashboard
No items found.
Problem & Context
Teams handle high chat volume across fragmented systems. Agents must hunt for context (who the user is, what just happened, current case status) before replying, which slows response time and creates inconsistent answers. LLMs can help, but without guardrails they risk inaccuracy, policy violations, or slow latency—eroding trust.
Business goal / Why was this product initiated?
ChatGPT (public product launch) → November 30, 2022 so we need to rapidly adopt this new normal ASAP
Customer Expectations agent to reply asap: eCommerce sellers demanded faster, reliable support without sacrificing the human touch.
Operational Bottleneck to scale CS team: Human agents were reaching unsustainable workload levels — ~7,000 messages/month/agent — creating scalability and burnout risks.
Financial Strain: Hiring additional agents to support growth would cost ~$600/agent/month, translating to $21,000/month for a 35-agent equivalent team.
Strategic Expansion: Scaling customer support for emerging markets (Thailand, MY, SG, PH) without linear human cost increases was critical.
User pain points
Customer service managers
Have to onboard new joiners; hard to scale training and customer service/support team
Chat agent human error
Agents overwhelmed
slow replies
Inconsistent tone and support from the same brand (with multiple agents)
AI hallucination - Robotic, Inaccurate and uncontrollable response from AI
Don’t know or have time to train and deploy AI
Chat agents
Constant tab-switching to gather basic context before answering
Rewriting similar replies; uncertainty about tone/policy compliance
Fear of giving wrong info; no visibility into source or freshness
Hitting platform limits (e.g., message caps) without clear guidance
End customers
Need instant support
Respond is not helpful
Unclear next steps and low confidence in the response
Success metrics
North star & adoption
Increase in messages sent by AI (this affects revenue)
Increase in AI full resolution rate
Quality & trust
Fewer AI escalations to a human
Fewer reports of AI hallucinations
Usability
Higher % of users who adopt AI on their first trial
AI trained with sufficient knowledge sources (coverage/recency)
Performance & cost (ROI)
Cost saved (human agent resource cost)
Agent time saved
Decrease in time to resolution (TTR)
Process & Research
Design process
We didn’t follow a traditional discovery process—because we’d already anticipated the AI trend, we partnered with developers to prototype new AI features before ChatGPT and similar tools became widely used. Our design process kicked in afterward, focused on solution validation through real usage rather than problem discovery.
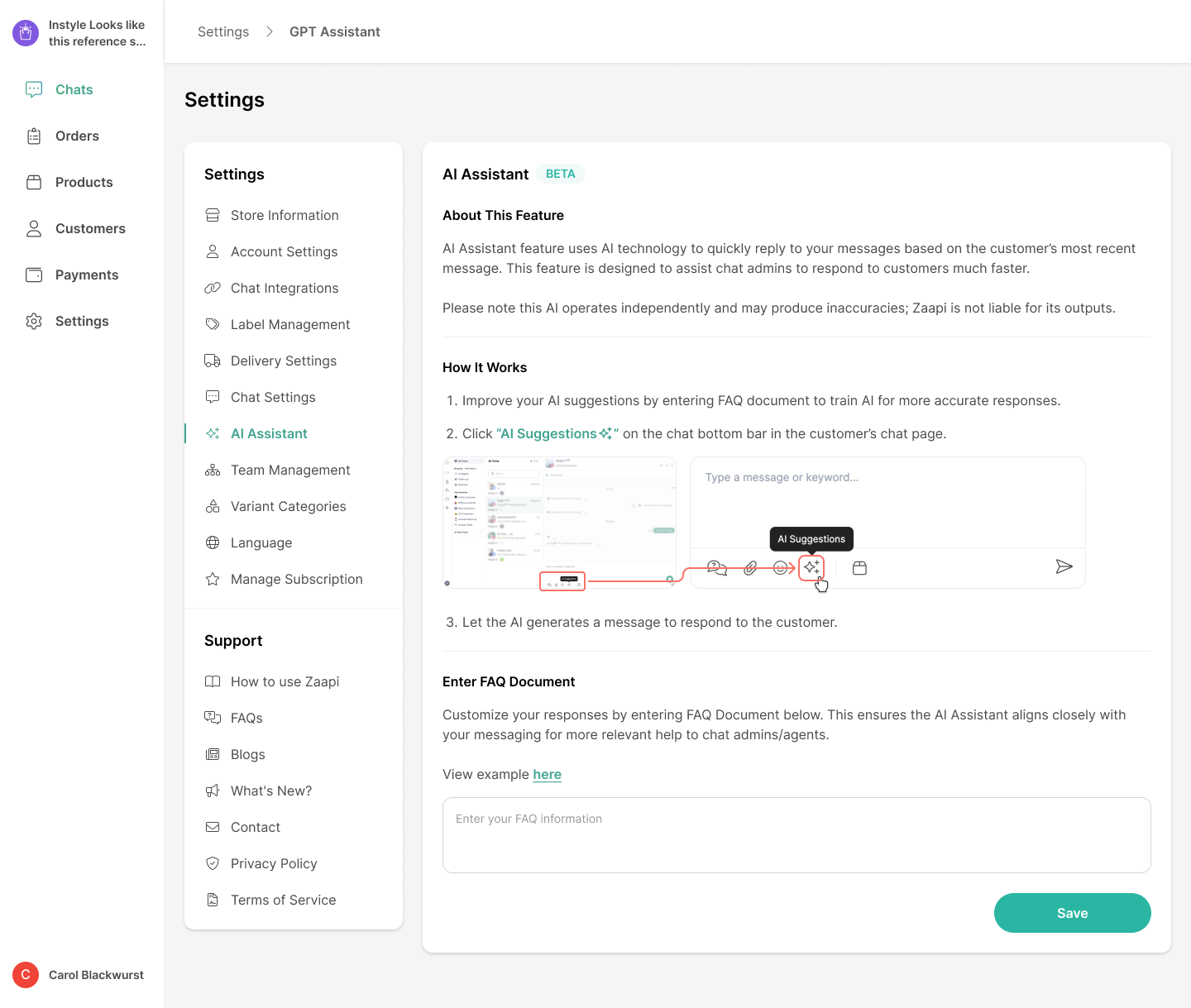
Before (MVP): This is Zaapi AI 1.0 (beta) in Sep 2023 — we don’t even call it a “chatbot” or “AI agent,” since it only generates draft messages for users. We’re cautious because AI can be unreliable at that time.
Our design process kicked in afterward, focused on solution validation through real usage rather than problem discovery.
Research methods
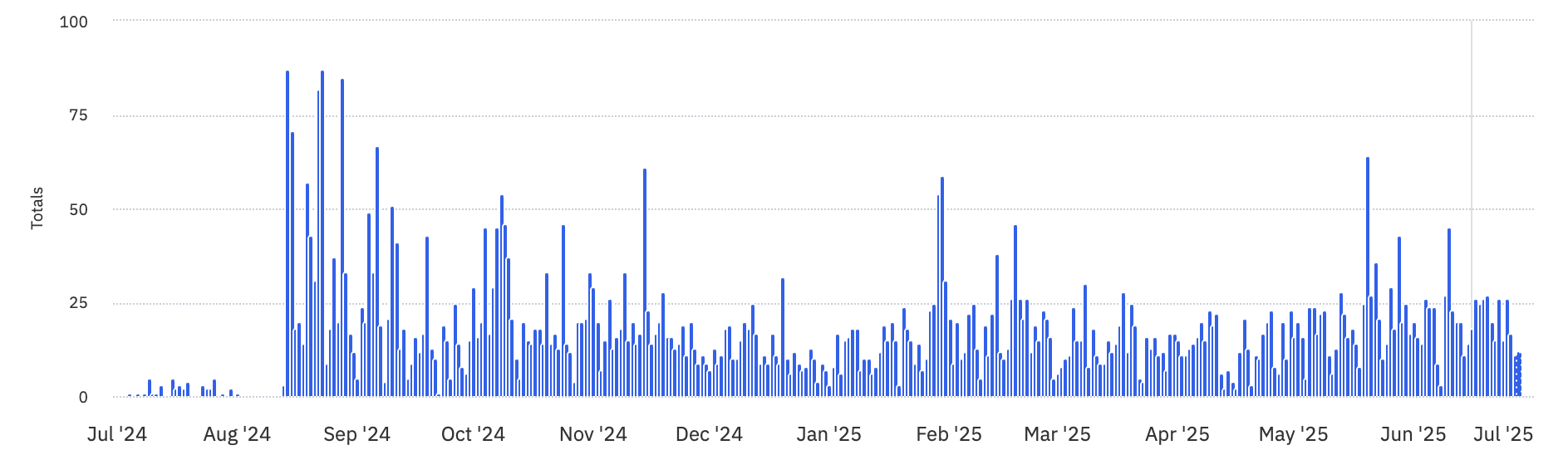
Solution validation in production: Released a lightweight MVP (answer suggestions), learned from real usage, then ran quick A/B-style tweaks—renamed the control to “AI response” and increased its prominence—boosting daily usage from ~10 to 85 events/day (+750%).
Workflow mapping: AI capabilities × Customer service workflow
Targeted interviews & evals: after launch, ran exploratory + solution-validation interviews focused on AI performance expectations and adoption; participants were managers overseeing AI agents and experienced AI users.
KPI & quality definition workshops in the interview: aligned on how to track resolution outcomes (full/partial), agent time saved, and AI vs. human handling volumes.
Key insights on AI feature improvements
MVP version validation
UI validation: Validated directly in the live app—renaming “AI suggestion” to “AI response,” refining its accent color, and moving the control into a more prominent spot for better discoverability.
After (Impact): That single tweak — switching the AI button from icon-only to an outlined icon + label — drove daily AI events from an average of 10 per day to a peak of 85, a +750 % surge.
AI capabilities
Technology: LLM, Generative, AI agent, Agentic AI
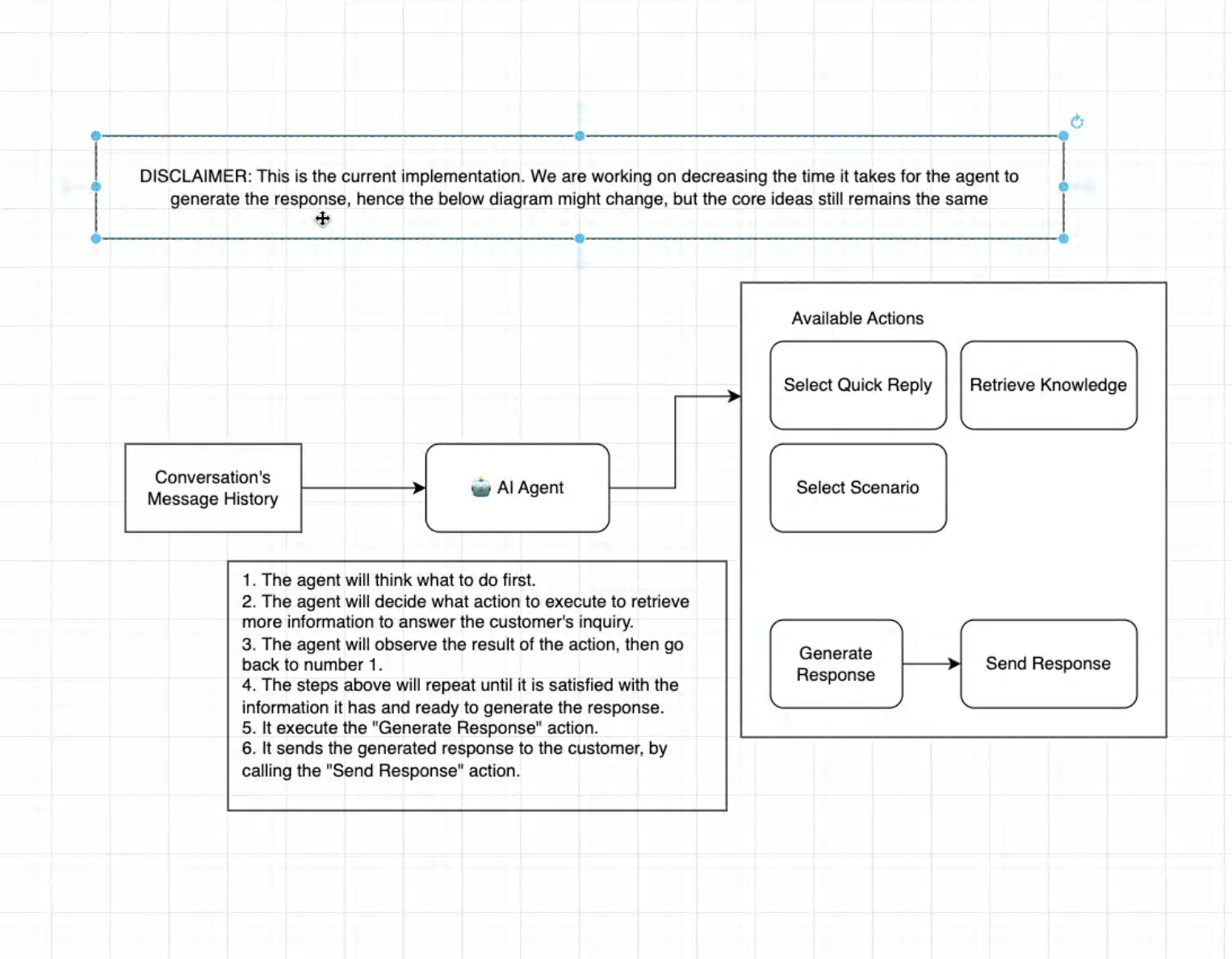
One message lifecycle (end to end):
Understand Detect language, extract intent and entities, score sentiment/urgency, and check policy eligibility. Output: intent, entities, risk/eligibility, locale.
Gather context (retrieval/RAG) Pull only the facts needed from CRM/case/history/knowledge, with source and timestamp. Output: context_bundle = {facts[], source, freshness}.
Decide (plan the next step) Reason over intent × context × policy to choose: answer_only, answer+action, or escalate. Output: plan = [steps] with confidence.
Compose (grounded reply) Generate a short, on-brand draft grounded in the context; include citations; control tone and length. Output: reply_draft + rationale/citations.
Act (tools / function calls) If the plan includes actions, call typed APIs (e.g., update status, create task) and capture results. Output: action_results + audit record.
Safety gates Enforce message caps/forbidden outbound, redact PII, apply confidence thresholds; fall back to clarify or escalate when needed. Output: approved | blocked_with_reason | fallback_prompt.
Deliver & log Send the grounded reply (and any action confirmation). Log prompts, context, actions, costs, and latency for audit. Output: delivered_message + full log.
Learn Collect thumbs-up/down and edits; cluster failures; update content/prompts; run offline evals before the next release. Output: feedback + improvements queued.
Intent mapping
Power-user input: Ask top agents/owners which requests they handle most in chat; review a sample of their recent chats together and tag the intents.
Log analysis (high-volume accounts): Run intent/entity detection on chat histories from our highest-usage accounts to quantify the top intents and edge cases; validate the list with those power users.
Output: ranked intent list with examples, required entities, and target action for each intent.
Power user #1 - Large multi-brand CS team
Order problems (damaged, incorrect, etc.) and sales invoice request: 10%
Order status: 40% (Handle cancellation requests with empathy)
Order requests and other questions: 10%
Product questions: 10%
Order card, product cards, nonsensical message: 30%
Power user #2 - Supplementary store
Common agent actions/chat use cases:
Check order status and inform the customer of the current delivery state
Answer medical condition questions accurately and responsibly
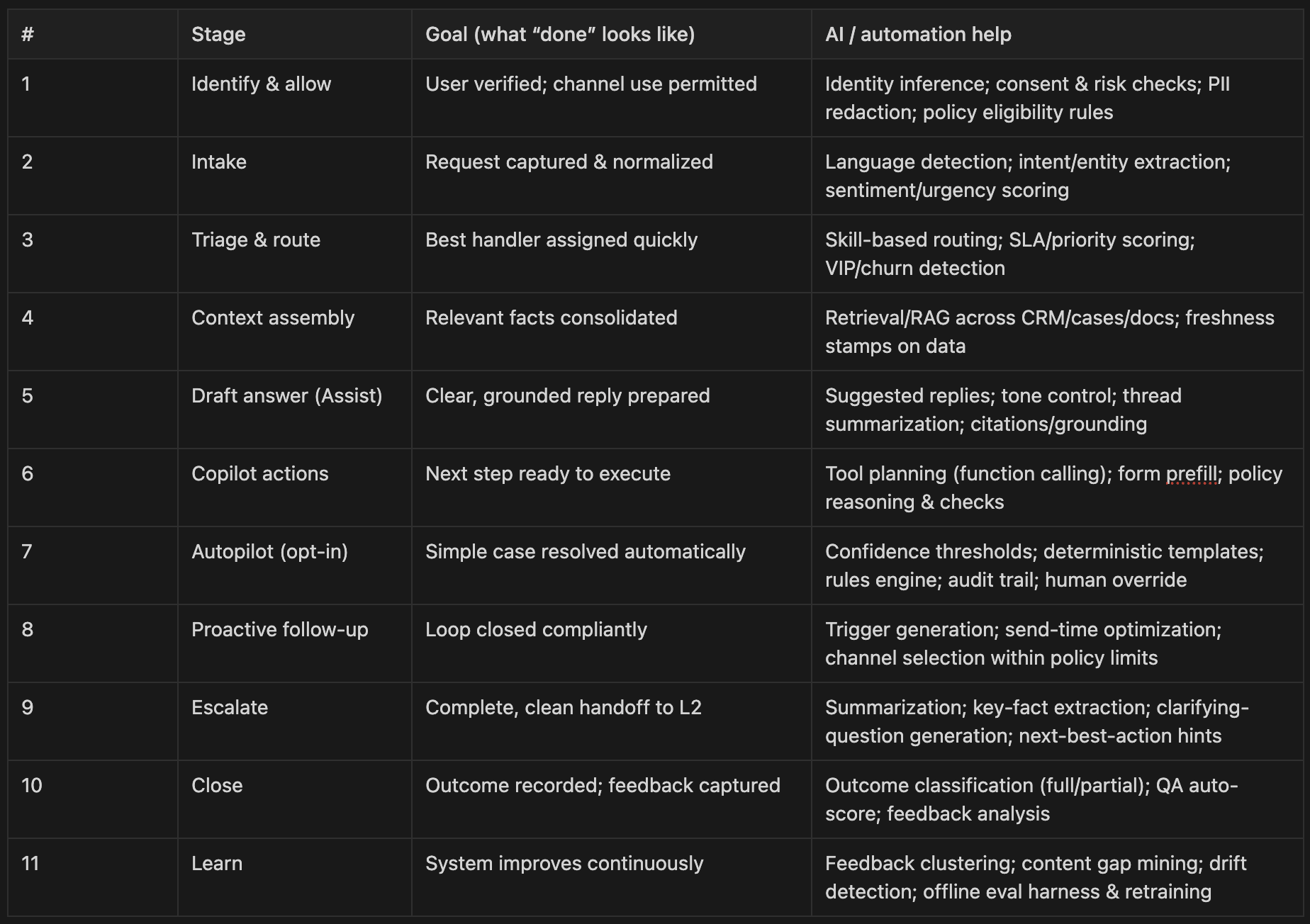
Customer service workflow × AI capabilities
End-to-end map of the service journey and the AI/automation that supports each stage—used to align roadmap, ownership, and metrics.
AI improvement interview findings (focusing on AI performance)
Research objective
Primary goal (exploratory interview)
Understand what real users expect when it comes to measuring AI performance in customer service — including how they track key AI-related KPIs such as resolution rate, enquiry categorization, and CSAT — and how these metrics reflect the impact of AI on team efficiency and business outcomes.
Secondary goal (solution validation)
Explore users’ experiences activating, training, and using AI chatbots — both within Zaapi and on other platforms — to identify key pain points, gaps, and opportunities for improving AI feature adoption and usability.
Participant criteria for AI performance & adoption study
Primary persona: Managers adopting AI agents to support their companies and tracking AI chatbot performance
Secondary persona: Experienced in AI activation, training and usage
Solution validation for AI‐chatbot setup
Key insights on AI feature improvements
Quality of AI responses
Empathy & accuracy audits: QA manually reviews AI replies to ensure empathetic tone and correct information.
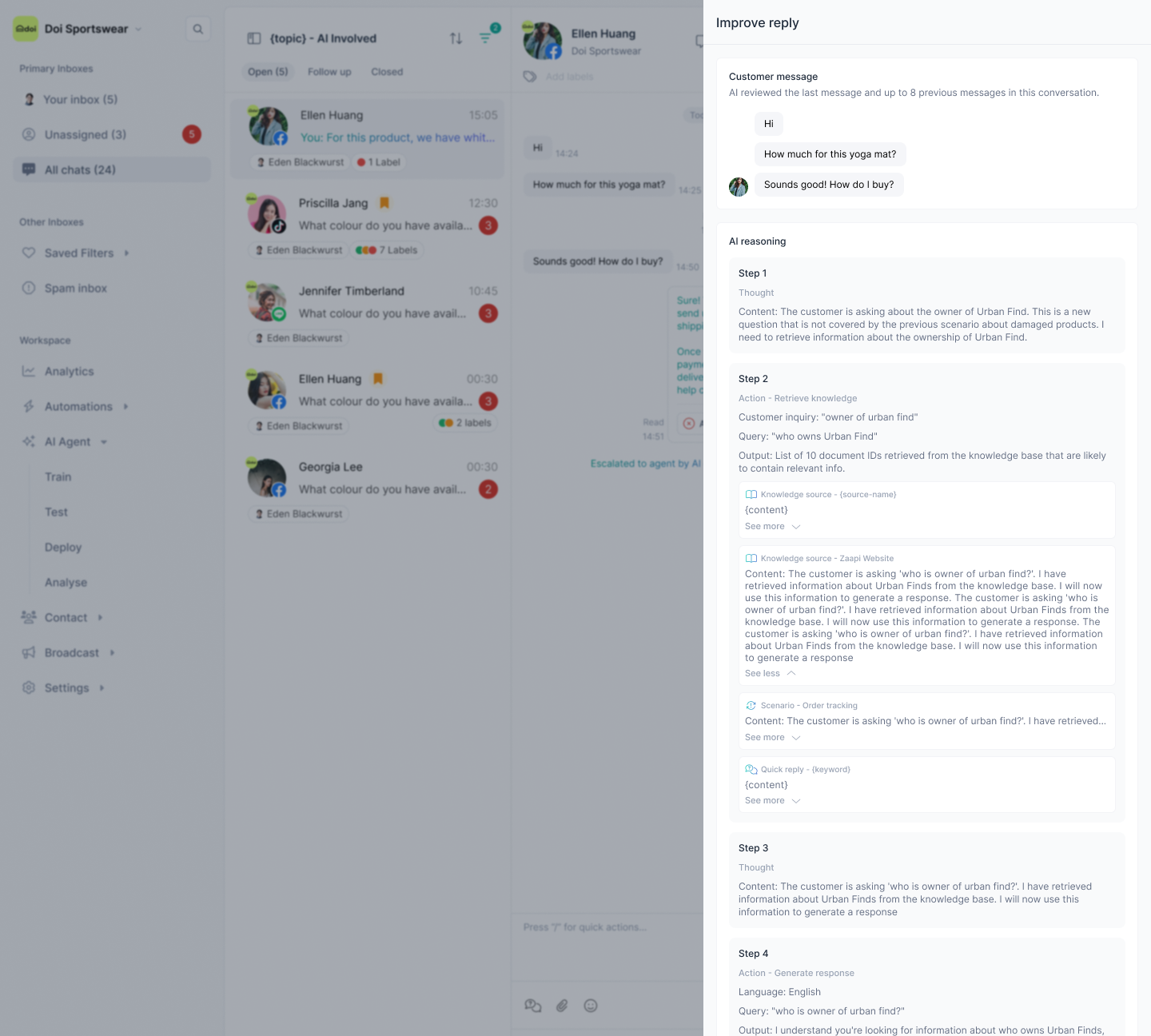
Transparent reasoning: Surface the AI’s decision process and source data for each response to build trust.
Guided training & gap remediation: Provide clear templates and data-format guidance, plus a consolidated “escalations” view with suggestions to fill content gaps and improve AI accuracy.
Expectations for AI performance tracking
Reduce agent workload: AI serves as the first line of defense, escalating only when needed, to lower human-agent staffing requirements.
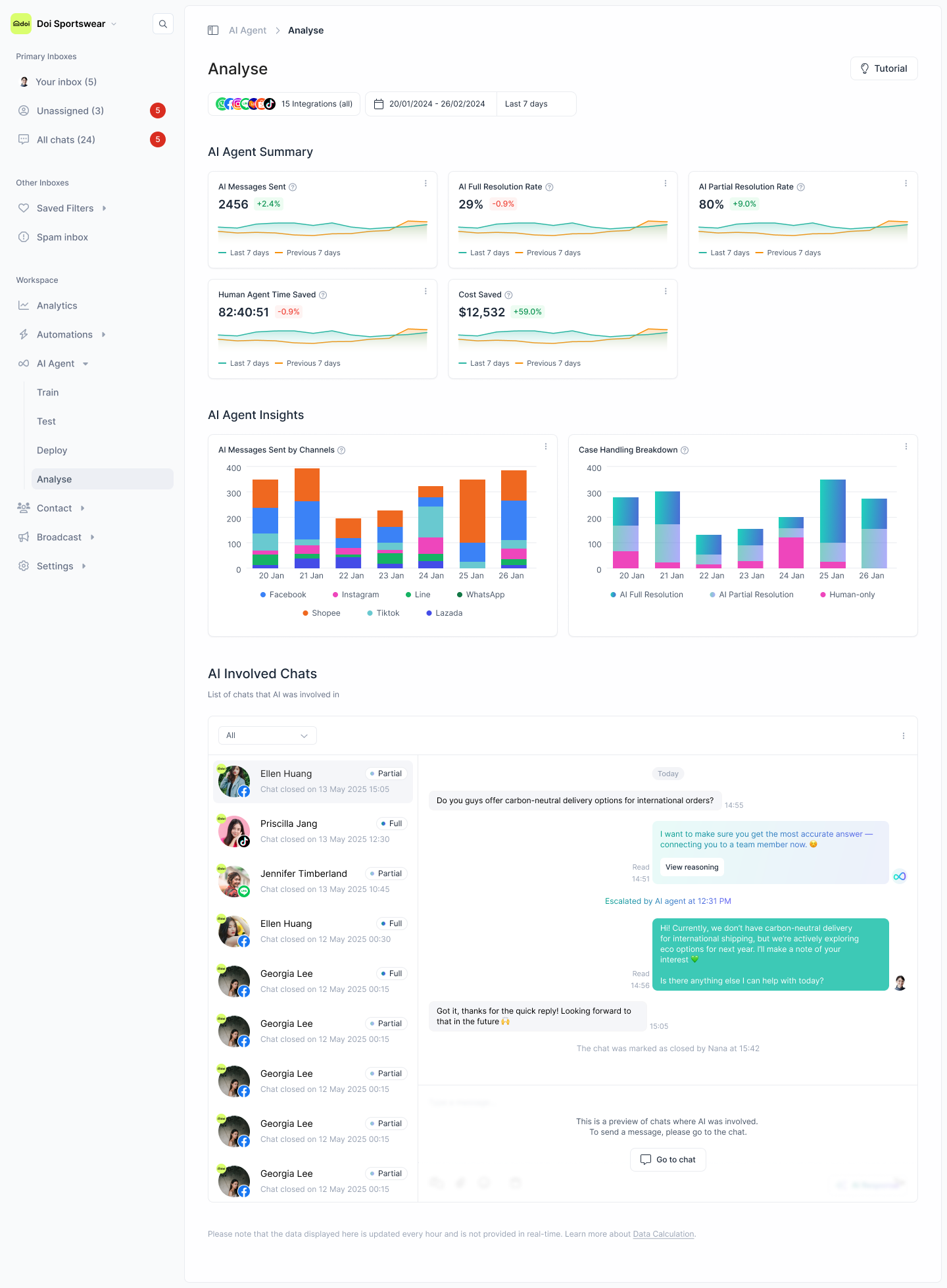
Key metrics to track: Full vs. partial resolution rates, agent time saved, and the volume of chats handled by AI vs. human agents (filterable by channel and account).
Clarification on “AI-closed chat”: define exactly when and how a conversation is considered closed by the AI.
Case management tracking
Categorize by intent: Tag each chat with an intent category to monitor daily case volumes received.
Monitor AI escalations: Track conversations AI could not resolve due to missing data or insufficient training, and use these insights to guide targeted data updates and resource allocation.
Feature prioritization
Prioritized by impact on resolution speed/trust × implementation risk × measurability:
Discoverability of AI features (starting with AI draft message then AI training and deployment)
Clear “AI response” entry point with strong affordance → Change copy to AI draft
Button placed at the chat screen (most used screen and where the user will use)
Rationale: fastest path to measurable usage uplift (+750% after tweak) and feature discoverability.
Escalation & Training Loop
Train AI by knowledge sources (websites text, .pdf, .csv, etc), SOP (standard of procedure), and personality training
Intent tagging, “couldn’t resolve” reasons, and a consolidated Escalations queue with fix suggestions
Guided content/training templates to close gaps from seeing what AI replied
Rationale: converts failures into system learning.
Explainability of AI thinking
Show what data the AI used and why; confidence hints
Rationale: increases agent trust; reduces user feedback and questions about AI reply
Performance Analytics
Full vs. partial resolution, AI vs. human volume, agent time saved, cost saved
Clear rule for when a chat is “AI-closed”
Rationale: aligns stakeholders on success and performance
Action Handoff (next phase)
From answer → suggested next actions or do it with granted authority (update status, send confirmation, create task)
Ship behind flags; expand based on adoption and quality signals.
Solution
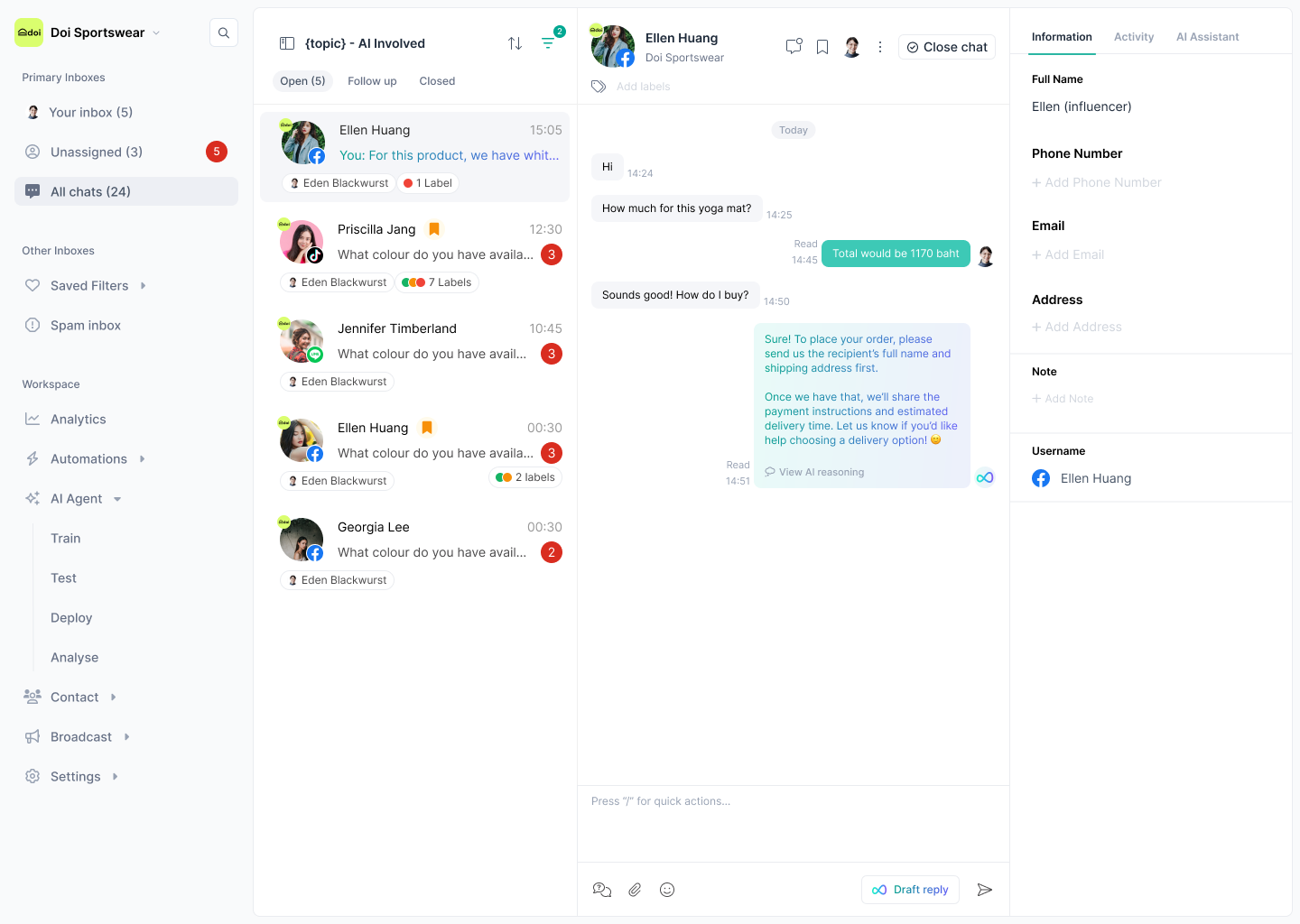
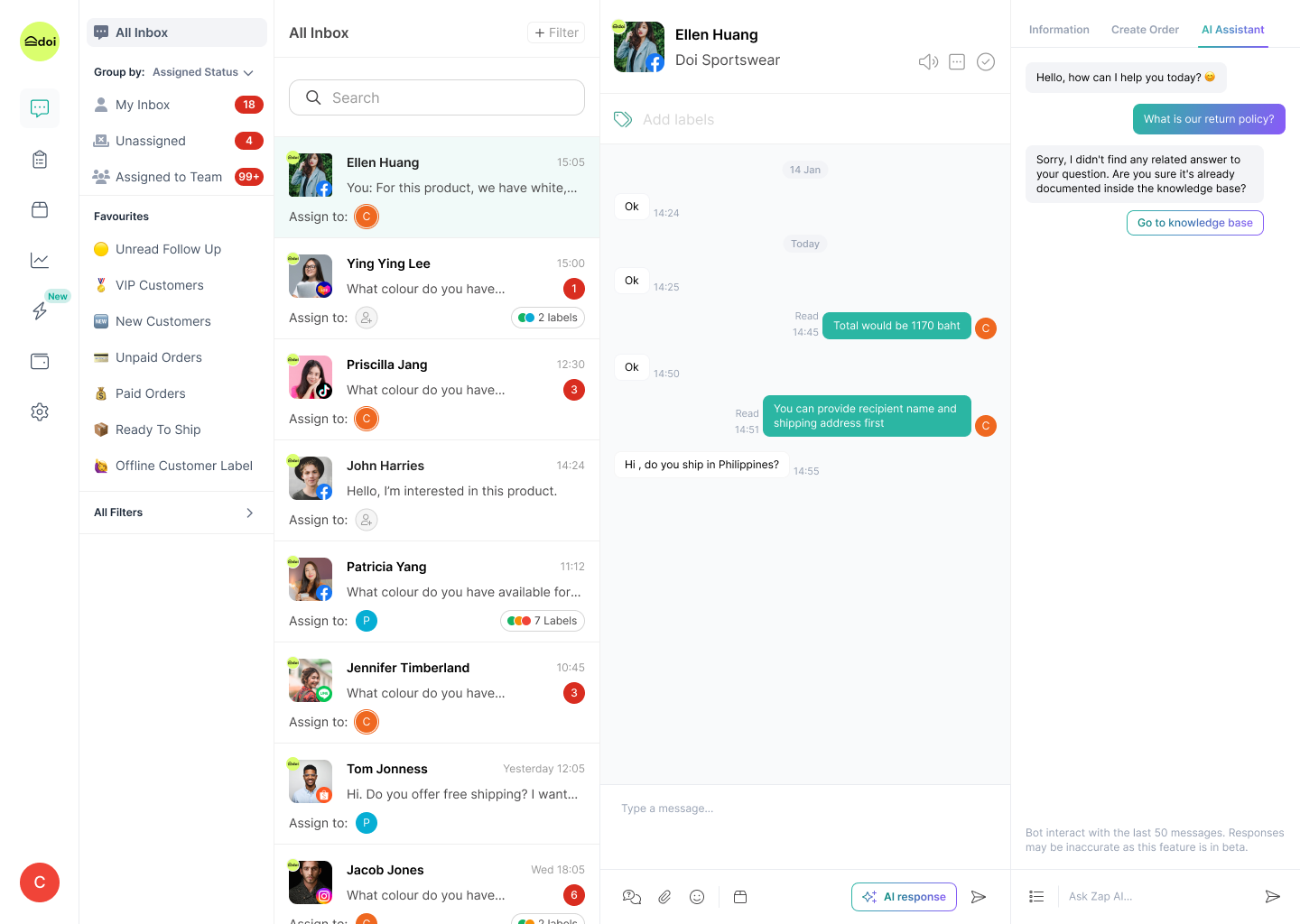
Chat screen & AI reply
AI thinking
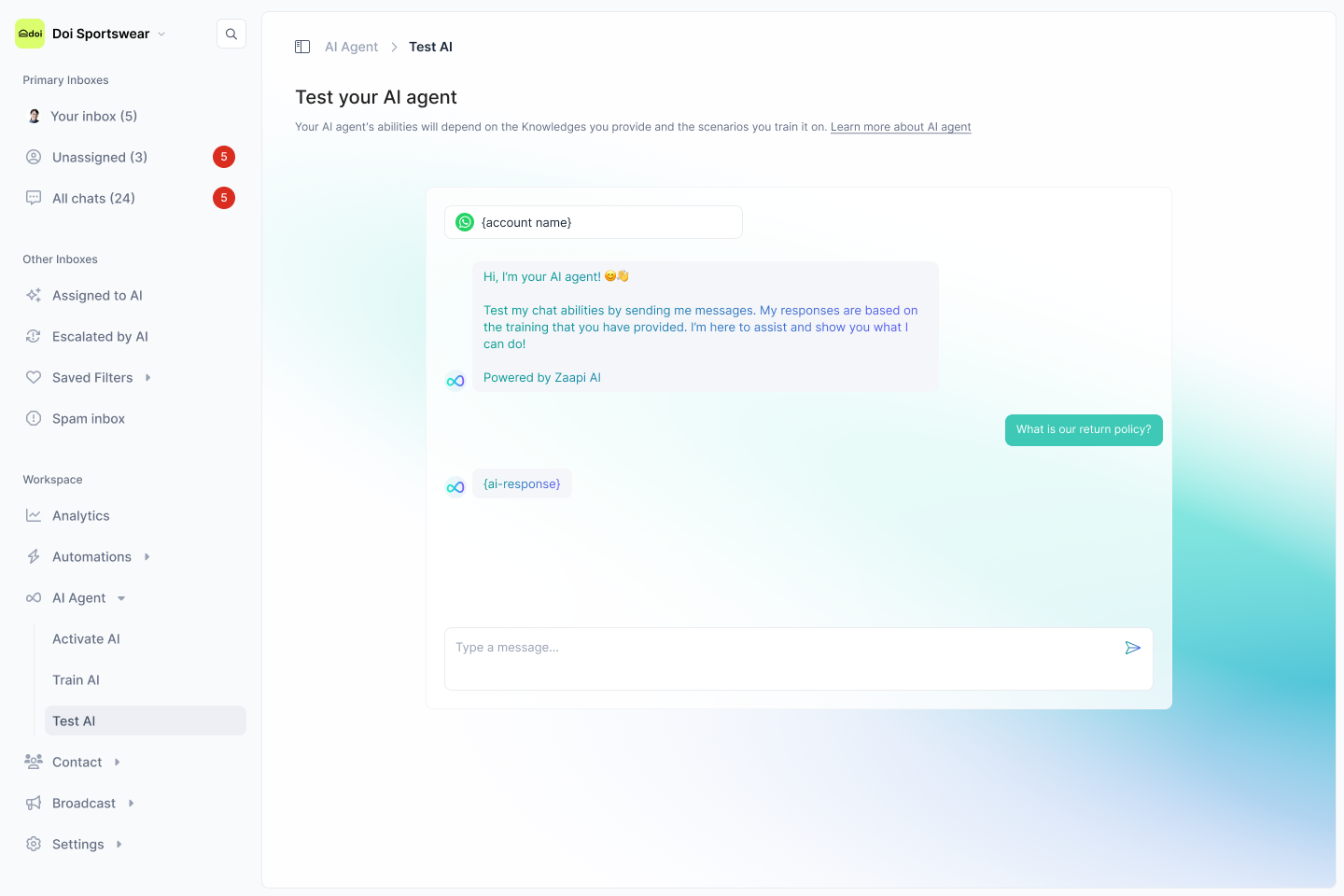
AI testing
AI performance dashboard
Reflection
For AI agent (unvalidated market)Entering an emerging space, we leaned into rapid prototyping and “learning by doing.” Embracing quick experiments (and inevitable failures), we stayed close to real users—iterating fast on feedback to uncover the right product–market fit.
What worked & Why
Start small and move fast. We shipped a simple first version, met weekly with engineering and data, and used one shared set of numbers. That let us deliver quickly and learn from real use.
Show the source and give testing environment to build trust and. Every AI answer showed where the info came from and when it was last updated. We tested in a safe test environment before launch. This made people confident to send replies and cut “AI is wrong” complaints.
Make performance easy to see. After the feature worked, we added clear dashboards: accuracy, speed, cost, and which sources the AI used. This visibility helped teams adopt the feature and improve it.
What not worked & how I’d do better next time
Architecture created debtWe tied AI training sources to the account. Every new source had to be mapped to that account. This was fast to ship, but hard to reuse and doesn’t scale to many teams or brands.Next time:
Create a top-level AI Agent.
Attach its datasets, policies, and tools once.
Let users assign an agent to a chat/inbox/account, with per-chat override.
Why: simpler to understand, easy to reuse, safer controls, scales better.
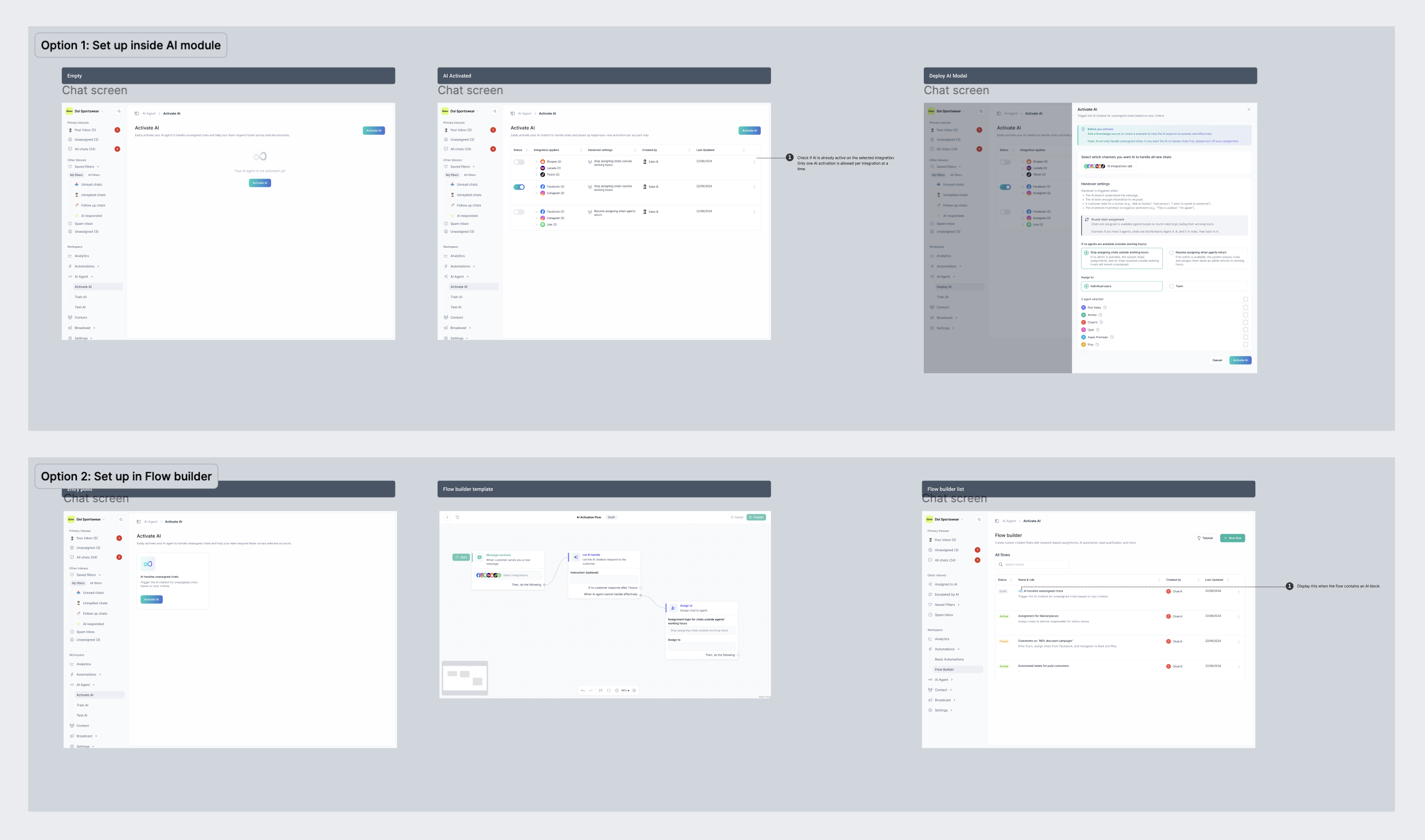
Deployment UX was too simple for power usersWe launched with a single page and an on/off toggle. Easy to start, but not enough control for B2B users.Current approach:
Flow Builder or Template: trigger → conditions → action (“Let AI Agent handle”).
Why: gives a quick first run and the customization advanced users want.
No items found.
Let’s do amazing works together!
See at a glance what I can bring to your business and team.